Crucible: The Oxide Storage Service
So, Adam, I'm gonna tell you, words you don't wanna hear.
Speaker 2:Namely
Speaker 3:Good. This could be anything, like, literally anything.
Speaker 1:In the the wheel. He's like, there are so many words I don't want to hear you say that wheel is so big.
Speaker 3:Where is this going to land?
Speaker 4:How many of the words are l l m? Like
Speaker 1:No. No. No. No. No.
Speaker 1:Okay. Thank you. Quiet. In other words, they're all l m. But I have been thinking about our episode from last week.
Speaker 1:I know you're just like, oh,
Speaker 3:Brian, we did the episode last week.
Speaker 1:No. We never talk about it again.
Speaker 4:That's why
Speaker 3:You and nobody else. Yes.
Speaker 1:Right. Okay. Right. So and, in, in the spirit of more, answering questions that no one asked. So no, I was because I, I, it actually is, this is actually on topic because I was thinking like as I was I was relistening to it, as I wanted to do, and I think, you know, I didn't really get to the crux of what I kind of find deeply annoying about Nate Silver's list of, you you know, the top, whatever top ten technologies from 1900 or from 2,000 and comparing them with the here's my, my, like the, the fundamental issue is it's reductive.
Speaker 1:That's the problem is that it's reductive. And I actually like things at take seem that where you have seeming simplicity and you actually there's, there's a world of complexity underneath it. Like that to me is actually a lot more interesting.
Speaker 3:And he's I'm glad you have the week to think about that.
Speaker 1:Yeah. You know, like, look, this is why it's I w we're always better off. Like, this is why, like the talk talk that I prepare when I get trolled is actually like listenable versus like the podcast, which may not always be, because it's a little little too hot. But no, but but I mean, this is the issue. Like, the issue is it's it's too reductive.
Speaker 1:And I think that it is too easy to take things for granted because we because technologists spend a lot of time trying to make technology integrate into the the into society bluntly in terms of, like, how we use it. And we don't want these things to be a giant pain in the ass. You shouldn't have to know how PCB works in order to be able to use 1. And or and I think, like, that is, like, the fundamental issue. And as, you know, I kinda think about my own interests, and I think that the interest of a lot of folks that are are, are friends of oxide, It it is the the things that are interesting are where you you take something that, like, wow.
Speaker 1:That how hard can that be? And you take it apart, and you realize, like, wow. This is actually extraordinarily complicated. And you get great reverence for, like, wow. I I'll never think of a network switch the same way again because, wow, it is so deeply complicated.
Speaker 1:I will never take boot for granted again. I will never, I I will never take all these these kind of unseen aspects of the system that are in this category of how complicated can it be. It's like, well, glad you asked because it's super complicated. And I think that that's the thing. When you just take that complexity and and in Silver's case, he's like, doesn't know that it exists, so it's very easy for him to will it away because he doesn't it it you know, not to sound, you know, well, I guess this is just gonna sound terrible, but I this is the the challenge of when you have someone who doesn't is not actually a technologist kind of weighing in on these things.
Speaker 1:It's like you can do that, but you have to have great reverence for this hidden complexity. And you you have to fight the urge to be reductive. So that brings us With that.
Speaker 3:To our simple storage service.
Speaker 1:To our simple storage service. No. I actually, that's a great example. Right? Because that is I mean, that's actually that's a that's very on point.
Speaker 1:I mean, how many people know that s 3 is actually the simple storage service, and it ain't simple. I mean, it's anything but. And storage is kind of the neeples ultra of how hard can it be and how hard can it be to, like, just
Speaker 5:Taking bits and you're putting them over there. I I can't play bits. You're just moving things.
Speaker 1:Just moving things. Take the bits and store the bits. When I ask for the same bits back, give me the same bits. Like, really? Is that complicated?
Speaker 1:And, Alan, I think it's it's complicated is the answer. Yeah. Yeah. It's complicated. So we've got so we're gonna dive into storage, and we and I I I think we have been Adam, you know, I have been remiss to to we this is a a dimension of oxide that we have really I know people rightfully think, you know, you people are such oversharers.
Speaker 1:Is, like, there anything that happens outside that you don't just prattle on about in 15 different podcast episodes? And the answer is, like, yeah. There are still a bunch of things that we haven't really
Speaker 4:talked about. Stay tuned. Stay tuned. We will,
Speaker 1:and storage is a big one because the storage is really really important, in the rack, and we haven't really talked about storage at all. We kinda hit on it in and it's open source, so we've had people out there they've been like, hey, when are you guys gonna talk storage? It seems really interesting. So, in the spirit of that, we got a bunch of folks here have been working on crucible, but, Adam, I wonder if if you and Josh might kick it off with kind of the origin of this because we were, when we started the company, we knew that we were going to have what one might call hyperconverged infrastructure. Hyperconverged is that how how much does that term bother you, Adam?
Speaker 5:It's a
Speaker 1:I think tremendously. I I won't be on
Speaker 5:the list of words you didn't wanna hear from Brian.
Speaker 1:That he is.
Speaker 3:Yeah. Yeah. Yeah. Yeah. That was the that
Speaker 1:I if I was writing a
Speaker 3:little note here and I turned it over and you finally got there. But I think because it sounds so kind of highfalutin and it is
Speaker 4:And yet also, I don't know what it means.
Speaker 3:Yeah. I think it's it's not it's not well understood, generally. And, it it it really sounds magical. I mean, not just converged, but hyperconverged. Yeah.
Speaker 3:You know? The the type of convergence.
Speaker 4:Critically, that's because we already had something that people were calling converged. Right?
Speaker 3:There we go.
Speaker 4:Before that. So Yeah. And I also don't know what that means. So, like, you know.
Speaker 1:You know, Adam, that dimension hadn't even occurred to me. That there's like a converged is kind of like a Boolean property, and it's like, no. This is not just true. It's hyper true. It's like
Speaker 4:You can't be hyperpregnant.
Speaker 1:Right. Hyper on. It's like, isn't it just all right. No, it is. It it's a goofy term.
Speaker 3:It's a good thing to and and people are using it to mean that, you know, sort of you get storage and memory and, CPU all sort of in blocks together. Is that is that roughly Isn't
Speaker 4:isn't it meant to be so I vaguely remember EMC selling us a ridiculously expensive storage card that was both fiber channel and Ethernet and calling it hyperconverged in, like, 2000 environment.
Speaker 1:No. No. No. That is not no. No.
Speaker 1:That is not well, this is an important distinction. That is merely converged.
Speaker 4:Ah, I see. That is actually not Well, I can see where my confusion would have emerged from.
Speaker 1:That is converged. That is the the converged was a kind of a, storage ism or converging these different storage protocols. And hyperconverged is the, I I've always understood your understanding as well, where you've got compute and data at some level co resident on the same infrastructure at some level.
Speaker 3:Yeah. And, and I mean, it's so specific in some people's minds that they feel like a detractive property of hyperconverged is that it all comes in some sort of fixed ratio. And I don't know why why the definition in their minds has become so specific, but, it's it's even a term that I've shied away from when talking about oxide at all, just because it comes with so much hair on it.
Speaker 1:And what's an abbreviation? It's HCI, but not which is not human computer interface, so I always thought it was, but,
Speaker 6:hyper infrastructure.
Speaker 1:Yes. I'm sorry. Hate to be doing this. It's true.
Speaker 4:Well, host controller host controller interface in the USB spec? I mean
Speaker 1:A distant dirt.
Speaker 3:Josh was already mad when he thought we were talking about Fibre Channel. Now imagine it. No, no. Exactly.
Speaker 4:I look, Fibre Channel, it's I mean, other than
Speaker 3:You know, other than other than
Speaker 4:how ridiculously expensive a tri street is, like, missus Lincoln, I'm sure it's fine. Otherwise
Speaker 1:I actually have a complicated on FibroChannel because the, you know, we did a this, you know, I mean, I worked on the storage appliance, and, one of the protocols that we ended up offering was Fibro channel. So I spent a bunch of time with FC and I'm like, you know, I I I kinda, like, like it in a strange way. It feels like you you know, Josh, you might actually like fiber channel. Have you gone do you know why? It's got that that kind of that that that that antiquarian sense to it.
Speaker 1:It's kinda it's, it's fine. Steampunk? We have
Speaker 4:a lot of it.
Speaker 1:It's steampunk. It is definitely steampunk, but, also, I didn't mean to suffer at its hands. That's, that's also cool.
Speaker 4:Like, I mean right. I I do believe in my heart of hearts that EMC could have used any protocol to create the nightmare cathedral that they sold us. So, like, Sound accepted. That's right. Yeah.
Speaker 4:Like, you know yeah.
Speaker 1:Alright. So to get to in terms of oxide, so we do so when we start out 4 years ago, we know we're gonna have storage as we we I mean, early early on, this is where we're, you know, students of all of the other efforts in this domain. And one of the dimensions of failure was, relying on third party storage. So building compute that would be then entirely dependent on third party storage because that's just a one that is a never ending quest to deliver a reliable system across 2 different vendors effectively. And you just can't own your own fate.
Speaker 1:Because, Adam, I don't know if you even seriously we didn't seriously contemplate. I don't think we seriously.
Speaker 3:I don't I don't think so. But in in part because it it's not just sort of, or or maybe some of this experience came from Delphix where where I worked for a bunch of years. We were, we dealt with lots of what what we called externalities. So we built this software virtual appliance that plugged into any storage you happen to find. And geez, like, man, we found like, every vendor's storage problem got bubbled up to us.
Speaker 1:Okay. And so we're not
Speaker 3:always guilty until proven innocent.
Speaker 1:I gotta ask you, at that time, when when you kind of first come because, you know, you and I have developed our own storage product and we've absolutely suffered with all of the ways that you suffer when you do up a storage product. Then you go to Delphax, we're like, hey. Good news. We're not developing storage product. Yeah.
Speaker 1:It's odd.
Speaker 3:I want to get out of hardware. Like, please just get me away from this baloney. Right?
Speaker 1:Right. And now you realize, like, no, wait a minute. I haven't gotten away from the problems. I I've merely exported them to hostile actors.
Speaker 3:That's right. That's right. It's just everybody else's problem has become our problem. And then, you know, for example, we saw some ZFS checksum errors when people were doing an EMC storage array upgrade.
Speaker 1:Impossible. Like, impossible. All of
Speaker 3:our Windows machines stayed up. Only you were complaining. Well, we're the only ones who have checksums jeepers.
Speaker 4:So Well, could you, if you consider turning those off? Because I feel like that's a little bit of help. Then you'd be fine.
Speaker 1:I mean, that must've been wild though, to see check sums on some, a piece of storage that people paid a lot of money for. That must have been like, I think it was tested on this one.
Speaker 3:Yeah. It was. Yeah. I mean, it it and then the fact that, you know, as you might imagine, the but the vendor and the customer were unwilling to accept any evidence to the contrary.
Speaker 1:Yeah. Definitely. Like, let me give you my evidence the contrary. I paid way too much money
Speaker 3:for these checks on
Speaker 1:errors, pal. So why don't you go reconsider whether I saw some checks on errors?
Speaker 4:There is a very like, a big, like, what's the thing where you fall in love with your captors?
Speaker 5:Like
Speaker 3:Stockholm syndrome. Yeah.
Speaker 4:Stockholm syndrome. So it's like combination combination Stockholm syndrome and, like good money after bad fallacy sort of. Yeah.
Speaker 6:Yeah. Yeah. Yeah. Yeah.
Speaker 1:And then, you know, all other the ways that people are are are secured into their infrastructure. Sorry. So you you'd had that experience of having the now you're just debugging every vendor's problem effectively. Yeah. Yeah.
Speaker 1:Yeah. Exactly.
Speaker 3:And and I and as you said, I don't think we really thought that, you know, oh, maybe we plug into somebody else's storage or something. I think as we envision this thing as, you know, private cloud, one throat to choke kind of kind of product, it wasn't nobody thought it would make sense for us to integrate with other people's storage products or, you know, drive APIs at other people's storage. It just made no sense. So we knew that we had to have storage in the box. And then there were a bunch of other constraints.
Speaker 3:One of the most like, I mean, some very hard constraints were we needed it to be reliable. And I think having built some storage products, we had a good reverence for what it took to be to make reliable storage. You know, we started at Sun. We started working on ZFS, I think in earnest, Brian, in like 2,001. Yes.
Speaker 3:That's right. And then we shipped it, you know, in, I think, 2005 as part of, like, the first update to Slayers 10.
Speaker 1:Right.
Speaker 3:And then we shipped it, you know, again, arguably as part of the ZFS storage appliance in 2,008. Yep. I think those felt like starting lines, but I think that was the time in my career I realized that or pardon me. Those felt like finish lines. That was the time in my career that I realized those were actually starting lines.
Speaker 3:Because Actually starting. We roll as, you know, we had shipped this thing. It was in customer's hands. This was in 2006 when we started the Fishworks Group building that appliance. And yet we were tripping over all this kind of stuff just in development.
Speaker 3:Then when we shipped the thing, we found our customers very helpfully helped us find all these other kinds of problems. So which is not to say that ZFS is unreliable or less reliable. I mean, we saw I saw this later on in in these even, you know, longer tenured products. But it's hard to build reliable storage.
Speaker 1:It's rare to build reliable storage because it's not merely about getting the the the block back that you stored, although it is certainly that. Right. And that is very much a constraint. It's about getting it back in a timely manner.
Speaker 5:Mhmm.
Speaker 1:Because I think one of the I mean, the problems that we had with ZFS, actually, I mean, in a real tribute to to Jeff and Matt and and the original ZFS team is the the CFS. We did not really we'd not see data corruption. You saw some very long data vacations. And Yes. Preventing data vacations is really, really, really hard.
Speaker 1:Preventing data loss is obviously a constraint. So and it and you just realize, like, how much damage a single bad disk can do to a broader system in terms of of a latency, not not in terms of of reliability. So it's it's really hard. And then the the the thing that I felt, like, I Josh, you and I learned very viscerally together at, at Joyant, where we do ZFS in production. And we did not I went there's a little bit of an asterisk on data corruption in CFS.
Speaker 1:CFS did not ever introduce data corruption, but we did actually have a very, very, very bad OS bug that, we, effectively push the system into a new dimension and hit some old behavior, hit an old bug, and it would cause rampant data corruption in the system. If you cause ramped data corruption in the system, like, you can actually it corrupt metadata on its way out that's already been checked.
Speaker 4:Critically in in the the memory,
Speaker 1:like, the
Speaker 4:RAM the RAM of the system.
Speaker 1:Yep. And when we did happen
Speaker 4:to be storing some data that was on its way to the disk, for instance.
Speaker 1:And that was very bad. And that was not right on the device. And so you really don't wanna have, like so basically, World War 2 stressful, rampant data comes from bad is what I'm trying to get this.
Speaker 3:Right. These are your life lessons.
Speaker 1:The these are my life lessons.
Speaker 3:So when we when we, you know, Josh and I started kicking around ideas for what storage would look like at oxide, doing as little as possible was an important constraint. I think at the time, you know, I joined, having done some research around ZNS. You know, this is what has now become flexible flexible data placement. But ZNS, zoned, namespaces on SSDs, and started thinking about, like, what are all the totally crazy things that we could go do from a clean sheet of paper? You know, at that point, we had almost 20 years of experience from ZFS and great system.
Speaker 3:But but really fundamentally a system that was built for spinning media. Like, it was it it had a very different design basis than, than what we have now than the state of the state of the world now. And I'd spend a lot of times with Matt Aaron's batting around ideas for what a next look like. So briefly fell in love with what a next generation could look like with all the wizziest new SSD technologies. But then with time constraints and knowing how long it takes to make one of these things, make make a storage service actually reliable and perform well and not go on long vacations, we started to figure out what the simplest form we could take.
Speaker 1:Right. And we I think also people might be a bit surprised as I guess they were with RFP 26 and our Helios discussion a couple weeks ago. ZFS was not necessarily a foregone conclusion. It was something that we all had a lot of experience with, but we also wanted to make sure we were really surveying things. So Yeah.
Speaker 1:The r p sixty, which we've just put put out there today, made public. Folks can go look at some of the things that that you looked at. But we did I mean, we, you know, very seriously considered things like SEF. Yeah. And, Adam, I remember you and I had some discussions with people who had deployed SAFE.
Speaker 1:Yeah. And they were reviewing. I mean, because, I mean, it it again, not to not to fall into the kind of what I'm convincing what I'm accusing Nate Silver of. I don't want to be too good back in here. But I think that it was very clear that Seth needed I mean, it the most charitable thing you could say about Seth is that it very much requires operators.
Speaker 4:Yeah. It needs a staff. That's the Yes. Peep of people who are not just, like, using it, but but but actively caring for it and feeding it and watering it, like every day, checking to make sure that the print queues are not clogged up or whatever it is. You know, like you need people doing the busy work basically to to keep it going.
Speaker 3:And it sounds like Brian, we had the same recollection of that, of like that conversation, which were, with some operators of Seth who were very, who give a lot of praise to SEF. Yes. But they're very close to that. Totally. Because the death was them saying, but you you know that Seth is operated, not shipped.
Speaker 3:And I've I've since found I've since found some people who kind of have pushed back on that notion, but I found at the time that very compelling. That this is a system that requires care and feeding, and it's great. And, we needed something that was going to be, autonomous.
Speaker 1:And that's been one of
Speaker 4:our core load stars, right, for the whole for everything that we've designed in the product, I feel like. It's like, how can we make this, truly automatic so that it does not require a person to go log into a Unix shell and, like, kill a stuck process or delete some files or move some logs around or whatever. Like, it should just work.
Speaker 5:Yeah.
Speaker 1:And I think, you know, Seth has been on an interesting journey, and they did an entire rewrite, which actually, paradoxically, kinda drain confidence that might have in it because they had been kind of so confidently asserting their previous data store that they were then, like, actually, ignore what we said about the previous data store. Now we've got one that works. And, I mean, like, I think it's great that Seth is, you know, living its best life and I'd be perfect for it, but it was it just was not gonna be a fit for us. So and then I think we and you kinda gone through some other things and really had decided, like, what what we need to go do is build something that is as simple as possible, as robustly as possible, and that can deliver what we're trying to deliver, which is reliable elastic storage to folks that are provisioning VMs on the rack. So do you wanna know I know you and Josh were beginning the noodle on and getting, like, specific about, like, what would this architecture gonna look like?
Speaker 1:Because I think it's, like, this was in 2020, the pandemic hit by actually, Adam, did you in the RFD, we refer to an actual meeting that we have. You record all meetings outside.
Speaker 3:Is this the one with with, the the the disc vendor?
Speaker 1:No. Okay. No. No. No.
Speaker 1:No. Because this one where we are effectively, it's a it's a determination for 60 where
Speaker 5:we're Okay.
Speaker 1:Figuring out what our approach is. And, oh my god, the COVID haircuts.
Speaker 4:That would have been in June. Right?
Speaker 1:Yeah. It's in June of 2020. And it's like kinda like it's like in that era when we're all getting haircuts at home and no one had had yet gotten really good.
Speaker 5:You know what I mean?
Speaker 4:I have I have notes from that meeting, and they finish with the words good meeting with an exclamation mark. It was a good meeting. Just to tie that off.
Speaker 1:Just it was a good meeting. It was good meeting. Actually, you know what, Josh? You've got nothing. Maybe you were growing your hair out.
Speaker 1:I I have to say, hey, your hair looks great in that meeting. Adam, see me after class. But, no, this is us. You can see me and everyone else after class. I got the very much the same.
Speaker 1:My my my bangs were missing. So we had we, we we changed up after that haircut. But so what were some of the kind of the the approaches that you were considering when you were originally kind of So
Speaker 4:I think
Speaker 3:I I think we ended up saying, you know, ZFS is gonna be part of this. And as much as possible, like, we wanna lean on the things that ZFS is good at. And I think the as I recall, the the the 2 kind of major architectural things that we considered were so do we have ZFS and then plug in some sort of distributed storage layer underneath this where, you know, a particular ZFS data set could could talk to multiple, you know, backing stores virtual volumes that were remote. And Delphix at the time was also doing some work along these lines, so it felt like not outrageous. And then the other approach that we that we considered was, what Josh had deemed a a mux.
Speaker 3:And I think this is something, Josh, that you had been thinking about at Joyant for a while.
Speaker 4:Yes. That is true. I was do you remember, but I towards the towards the end, we were like, we could do EBS. Like and You're like no go back to bed that this No one No one that we would give it to within the organization, which we find ourselves would enjoy that. So
Speaker 1:We and and just to be clear, we did not all we had at at joint time
Speaker 4:was local storage.
Speaker 1:Yeah. Which was a, a hyperconverged s 3, if you will, a storage service that you could run your feet on. And so that was and then we had, effectively local of a I hate the term ephemeral because it wasn't ephemeral at all, but we had local storage that was local to an instance that obviously performed very well, but we did not have an EBS in between. Right. Yeah.
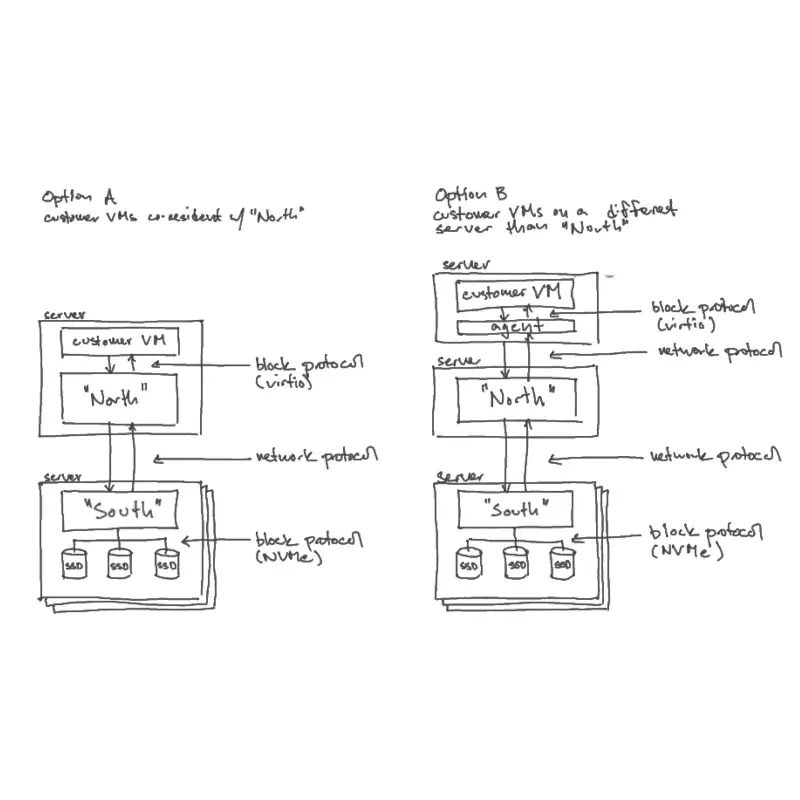
Speaker 1:And we knew that was gonna be a huge undertaking. And, Josh and so, Josh, I know you've been thinking about it, and that that kind of that first approach, that you're describing where you have ZFS on a so you've got a a local compute instance that is talking to a z pool. That z pool is then going out over the network underneath it effectively. That's what we call, I think, the southern volume manager approach and the
Speaker 3:That's right. That's right. You're right. As opposed to what what then became the northern mux where we had ZFS on those distributed nodes kinda managing each of the SSDs, carving those up into what we would later call extents, but, you know, within the datasets. But having this new layer that was running close to the to the VM, There was a multiplex in the IO across these, these downstairs components.
Speaker 3:So or or these southern components. And that later became upstairs and downstairs for, for north and south.
Speaker 1:Right. And the you know, as we're kind of consider these look like a major fork in the road. I mean, these are totally different architectures, really. And, you know, one of the things that I'm a big believer is, like, what can you go prototype or implement to get some to inform a decision? And, Josh, I think it was about at this time, you're like, I just need to go simulate some of this stuff.
Speaker 4:Yeah. In in June, Adam Adam went to start looking at, like, just a nominal prototype of the the thing with, like, disks underneath set of s. I think we started out with ISSCSI possibly in AWS. That's right. You did some tinkering.
Speaker 4:I have found a note here where, like, a bunch of your tinkering ended with, like, a one line comment that was, like, garbage with a period.
Speaker 1:Which sounds about right.
Speaker 4:Yeah. That reflects what I remember the the the feelings of the time being.
Speaker 3:Yeah. I I I do think I went in with with more optimism that that this was gonna sort of work out. Right? But it it was I mean, as I said, like, ZFS wasn't on its, you know, initially even designed for SSDs. So it certainly wasn't designed for different volumes that were remote and might be available and might not, and so forth.
Speaker 3:So, yeah, I think I think garbage was a pretty terse and accurate summary.
Speaker 4:I think my skepticism originally with the idea came from, like, the partition like, network storage, like, iSCSI, you end up with partitions. Right? This is not something you really get with, like, a local SCSI disk. It's either, like, working or it's electrically connected and it's not working and you can decide to, like, retire it.
Speaker 1:Well, this is a real danger at, you know, on the one hand, there's a power of the abstraction where it's like, oh, you think you're talking to a local that's, oh, surprise, you're bringing up the network. But on the other hand, come back here. You're noticing a whole bunch of new failure modes there that you didn't actually have.
Speaker 4:And Right. Things can go out to lunch for 2 minutes, and that's extremely bad. Like, you know?
Speaker 1:And this, you know, things of problems that, you know, NFS addressed one way or the other for better and for ill. But what we really not looking for something that has NFS semantics. We're really you do need something that's really got block semantics, not file semantics. Because what you're trying to support is a guest VM that's gonna do, you know, its interfaces, the machine interface effectively. So it really does need a block layer.
Speaker 6:Right. And
Speaker 4:so along alongside that, I worked on just a simulator for how I envisaged the, like, storage format and the protocol would work or the other approach where we would we would have, simpler non redundant ZFS pools down on every like every SSD in the rack has its own file system, own ZFS pool and file system basically, and there's no mirroring or raid or anything. And then we would do essentially replication from from from at the top. You know, we would write blocks of data to some number of replicas, which I think around then we decided would be 3 replicas.
Speaker 3:Yeah. That's an important point too because we decided we weren't gonna do anything, any crazy erasure coding or rate or anything like that. We decided we were gonna really keep it simple. Right. And and, not just mirror it once, but mirror so have 3 redundant copies of every block that that, customers store within the rack.
Speaker 3:Because we weren't trying to make the world's most efficient storage, the world's fastest storage, world's anything most. It was meant to just be a good everyday driver.
Speaker 1:Right. And in particular, it was meant to be, like, reliable above all else. Had to be absolutely reliable. Like, that had to be a constraint. Well, and
Speaker 4:a big part of big part of 3 replicas was like, if you recall really early, like one of the first things we decided was that if we if we did network storage and we did live migration, then software update could basically be like something that people don't notice because you can go and update and reboot each computer in sequence. And if you're if you only needed 2 of 3 replicas to be online and responsive to take rights basically without a durability loss, then like 3 replicas was the way to go. So
Speaker 1:Well, and this is actually an important point too because especially people who have followed us from company to company be like, wait a minute, didn't you guys like write a blog entry explaining why network storage is a problem? And it's a yes.
Speaker 4:Well, it is it is a problem. We spent 4 years, like, screwing around trying to make it work, and it's going well, but, like, jeez, a lot of work.
Speaker 1:Yeah. It's a lot of work. But part of the reason we viewed it as a constraint on what we were delivering is exactly what you said, Josh, is that like we knew we we needed to do one of the pain points that we had had is the the absence of live migration. And when you don't have live migration, you don't wanna reboot a compute node because you can't migrate it and you are therefore like, that node you want that node to sit. And there are that just has a lot of perverse incentives and it creates a lot of problems.
Speaker 1:So we don't wanna have any of those problems. We wanted we wanted to have live migration built into the product as a constraint on the on what we were doing. And that meant that you have to have network storage, as a first class operation. And you can do other things too, but we we really viewed that as a constraint. And so, Josh, your simulator begins to yield some results in terms of indicating, like, okay.
Speaker 1:Maybe, like, this this path of the northern mocks is feeling viable.
Speaker 4:Yeah. I had made made myself comfortable that that, like, we could build a crash safe representation of a disk with a reasonable performance like target in mind, without it being like, incredibly complicated, and we'd need to build a custom file system and a bunch of other stuff. Like the, I think the and the simulator stuff I did for, like, 2 months was a big part of that. Right? Like like the discovering, like, what happens if you allow an overlapping right to the same disk address, right, to to occur Yeah.
Speaker 4:To be issued, like, concurrently within, like, you know, like you're writing to lba 5. And then before that finishes, you write to lba 5 again. You know, and there's just like there's a it's all about ordering constraints really, right? Like this operation and this operation, like this one has to happen after that one because it's replicated. You're doing that operation on 3 copies and so that happens after relationship has to be the same on all 3.
Speaker 4:Right. So then there's just like an issue of like dependency ordering threading through the protocol and but you don't wanna make everything totally ordered because then you can't do anything in parallel. So, like safely splitting up what things can occur concurrently. How do we make sure that each replica ends up transitioning through the same series of visible states even if they end up doing things in parallel and then making it crash safe. So, if you, you know, get interrupted between or during any set of operations and indeed if you get interrupted during a different point on any replica that you can still come back up and figure out what it is that you've promised to give back to the guest.
Speaker 4:And discs have a pretty specific set of promises that they make around, write back caching and flushes and synchronization and what's considered durable and not durable with respect to asynchronous rights and so on. So the simulator was about trying to square those promises that we had to make against how we might implement that on the back end with a protocol because you were essentially creating a distributed system with not many nodes. Right? But like like one of the simplifying assumptions, I think that that we've held the whole time is that there is actually only one client. So there is no need for Yes.
Speaker 4:Yes. Consensus or coordination on a on a block by block or request by request basis.
Speaker 1:And Josh, when when did the nomenclature and I think Matt pointed out in the chat that the nomenclature at some point shifts from north to south. We shift from upstairs and downstairs, which I always have I mean, I I just get the the the image of a an English manner in which madcap adventures happen downstairs.
Speaker 5:With that?
Speaker 1:That is
Speaker 4:that's definitely where it came from. I mean, the I swapped 1, one historically toxic, politically charged set of words for another, but on a different context. News.
Speaker 1:We're not gonna have a civil war, and instead we're gonna have a class base.
Speaker 4:Right. It's merely about class.
Speaker 1:Maybe about class. No. No. It's it's great. Good stuff.
Speaker 1:And then somewhere so this is all kinda through 2020. And then in early but it's, like, it's clear that, okay, we've sketched out we need to go do. And, Josh, remember both you and Adam being like, by the way, I mean, we already have way too much to do, but, like, we
Speaker 4:need to add some people to
Speaker 1:go do this, pal. Like, we cannot do we there you know, we have joked that inside of oxide, we've got 9 different startups and this was definitely one of the startups, and it was, rather understaffed.
Speaker 4:I have a date here, 20 February 4th, 2020. So before the pandemic, we were in an all hands, and Adam says the long pole will be storage. Write it down.
Speaker 1:Like And you did.
Speaker 2:And you wrote it down.
Speaker 4:I have it here. Because Accurate, I feel, in hindsight. But we we didn't start on, first of all, until February 17th, I think, 2021.
Speaker 1:Well and and which is a good segue to Alan. So, Alan, you joined us, I think, in April of 2021. Is that what May. May. What is that?
Speaker 1:May. May. Yeah. And so, Alan, you're coming so describe your background a little bit and kinda how you're coming into oxide in early 2021.
Speaker 5:Well, I let's see. I had I've been at Sun for a while. I went to a storage startup through card data. I came back on and then went to another storage startup, the SSD. And I was had left there and and gone somewhere I wasn't really happy with, and I wanted to wanted to land somewhere working on big systems problems.
Speaker 5:And I was keeping an eye on Oxide, and finally, I was like, I I really wanna work there. I I wanna see if I can get a job there. But I'm sure that I mean, there's so many storage guys there. There's no way they need any more storage because I'm sure that work is like they did that in the first 15 minutes.
Speaker 1:Oh, yeah. Right. Yeah. Exactly.
Speaker 5:Back burner.
Speaker 1:Little did you know?
Speaker 5:Yep. So then I I show up, and there wasn't much storage done yet. But there was lots of good ideas. And so Adam and and Josh sat me down and said, okay. Here's here's what we were thinking.
Speaker 4:Here's the repository in which we've been phoning it in. Would you like to do the typing?
Speaker 5:That was sort of the the beginning. And and, yeah, we we got to work and and started writing code and
Speaker 1:Yes. And so describe that kind of journey. So you are you done you you had kinda come in with a background of you've done a bunch of storage. You've been, at at DSSD, at Sun, but I've also been doing some Rust at a at at a startup, if I recall correctly.
Speaker 5:A little bit. Yeah. Not not a ton.
Speaker 1:So you're coming into a, you know, some stuff that you you you've got a lot of experience in and and understanding, getting ramped up on Rust as well. And so what were were some kind of the first things you started experimenting with?
Speaker 5:I think it was it was implementing the the lowest part of what what Crucible is, talking talking to the files that we'll put that are the extents where we actually put the data on and taking sort of Josh's and Adam's ideas and and putting them into actually writing bits on disk.
Speaker 1:And what I'm talking about some of the early milestones when we were I mean, there was so much work to be done. But when we and I think I, you know, I I pretty early on in there also, you're like, hey. By the way, we we definitely need to add, I I cannot do this by myself. I'm gonna need additional folks. Yep.
Speaker 1:But what what were some of the I mean, when did we call the name Crucible, actually? When was that? I thought I thought
Speaker 4:According according to my according to my notes, the day that I opened the repository and started typing the first, like, 500 lines was when I decided to call it crucible.
Speaker 5:Alright. It was crucible.
Speaker 1:Like, that
Speaker 4:all happened in the space of about 30 minutes. So
Speaker 1:Alright. So we so it was crucible when you when you got here out. I got here. On your side. Okay.
Speaker 1:So, what, yeah, we do as you're so you're proceeding with some of the the kind of the earliest lowest layers, and, I mean, you've obviously looking at kind of the thinking that had been done on this and kind of what is your thought these people are off the rocker or this?
Speaker 5:I was a little little worried there were a bit too many layers. But, I don't know. I was just so excited to be here and to start working on it and and being able to use Rust full time. I mean, we've talked a little bit about how we like Rust, and I think that language enabled us to go so much faster than it would have been if we would have done it in c.
Speaker 1:Yeah. That's really interesting. Yeah.
Speaker 5:Like, no way would we have gotten as far as
Speaker 1:we did as quick as we did with with any certainly with seed. But And and then because I remember early on, you being like, we definitely need more folks here. And, James, you joined us, like, just a couple months later in 2021. Right?
Speaker 4:In July.
Speaker 6:Yeah. It was July. Yeah.
Speaker 1:And I I definitely, remember in the the conversations you're having at Oxide, you you made 2 deadly mistakes. You indicated to Alan that you're interested in storage. And then as I recall, you laughed at Alan's jokes, which is always the second I mean, the the Alan was was smitten the second you, the second his jokes were landing. It was definitely it it was a it was made meant to be.
Speaker 5:I remember the hiring huddle when we were talking about James. I was like, I I want James. I want James in storage.
Speaker 1:So It it was that direct. I then he also added, like, also he laughed at my jokes. But the, I think that James
Speaker 5:It was after I've
Speaker 1:seen it. Right.
Speaker 4:He's from the Commonwealth, so I can't argue with that.
Speaker 1:Exactly. You're, you're fine with anyone who's from a constitutional monarchy, hire them. Right. And so, James, you're coming aboard, and I'm not you had you had your your fingers in a lot of parts of the system, but but very, very much involved in Crucible. What were some of the the kind of your early memories of getting going with Crucible?
Speaker 6:It's funny that Alan started out, at the lowest level, in terms of Rust, you know, talking directly to the bits on, I guess, the downstairs at that point. I remember one of the first things I did is I I came up to the top and I said, okay, I'd like to put a, NBD crate in front of this. I wanna treat this as a actual, like, disc. I remember the, the demo that resulted from it. I said I was very nervous, and I think I said it's a disk, like, a 100 times in a row.
Speaker 6:But I I wanted to make that, you know, part of my development workflow. So starting with, like, can I interact with this, you know, /dev/nbd0, for example? So getting it up and running like that was one of my, one of my earliest memories, in that case.
Speaker 1:Well and so you mentioned the demo because I remember the those those early demos of where you're actually getting this thing to do, like, re you're actually using it for, like, real stuff. And we're, and there there nothing beats seeing a demo where where people are actually like, the stuff I've actually we've been developing, I'm now actually putting to real use, was just outstanding. And I learned that you're, because James has got a, Oxide has several data centers, one of which, in Canada, were all named after pet food names, I believe, or all your we do believe in in pets, not cattle for some some machines. Good old Fancy Feast, I feel, has served very honorably in the
Speaker 6:As the, as my comedy partner, Greg, likes to say, I'm one of the hyperscalers, and I will take no further questions at this time. Let me see if I could I have a picture that I actually took of this so I could drop it in the chat.
Speaker 1:Oh, yeah. This is great because you're solving another problem for Adam, which is, like, it's not this. It's gonna be my my northern mux diagram.
Speaker 6:Please don't use this as the, the background of the, like, the the final thing. Yeah. So this is, affectionately called the Canada region. It's composed of 4 machines that I, it's like the here's your RackBro kinda thing. It's it's it's all desktop hardware, but, it emulates as as face faithfully as I can make it, the oxide system.
Speaker 6:So you've got the 4 machines named after dog food there. That would be, Dinnerbone, and Fancy Feast is the control control machine at the top. And, yeah, I I regularly bring up and and tear down all the, required stuff just in the in the furnace room over there. I didn't actually put that around with the thing. Yeah.
Speaker 1:There are you have they've actually seen a photo of it. No. It looks so much more professional than it was. It not not to take anything. That that I'm a little disappointed.
Speaker 1:Are you do you disappointed, Alan? I'm disappointed. Yeah. Yeah.
Speaker 6:Hold on. I'll post the back. I'll post the back. It's not it's no longer professional when I post the back. There's no cable management.
Speaker 6:It's just everywhere. Yes. There's some I mean,
Speaker 3:I thought it was literally in his bathtub, so I'm very impressed.
Speaker 5:Yeah. Yeah.
Speaker 1:I I that's was my understanding too. I'm just I am very, I mean and now I can't get the image to go. There okay. The back, that's better. Better.
Speaker 1:Better. I feel. I feel can Allen step in the right direction on that one?
Speaker 5:We're moving there. We need a little I'm seeing you can see a little more, James. But, yeah, this is better.
Speaker 1:Yeah. I I I needed, you know, something, like, obviously, Canadian, like, you know, a a a flagrant foul after a, an empty net go or something. I don't know. I need I need something else in here, but this is good. This is the this is we're moving in the right direction.
Speaker 1:So but and, James, you were, because I also know that you were able to that that kind of approach of coming from the from the top down led you to develop some pretty important functionality pretty early on. I remember, like, the the snapshot that when you're developing snapshots.
Speaker 5:Well, and James also James was the first one, I think, to actually boot on a Crucible. Like, I I was testing it, but I didn't actually have it connected to a a VM. And James was the first one to actually boot a system on Crucible.
Speaker 1:Wow. That was been I mean, that was been exciting. See, when was that? I mean, this is where time really blurs together.
Speaker 5:Yeah. I mean, it wasn't too long after he arrived.
Speaker 1:And so we I mean, Alan, obviously, a huge shot in the arm to get someone who you're I mean, I think it's so important to be collaborating tightly with someone.
Speaker 5:I mean,
Speaker 1:I don't know. I did you find that it was I mean, obviously, it makes you go more than twice as fast, I feel, when you've got someone who you can, like, who who cares about the problems that you've just solved or the Yeah. Really I mean, obviously, we're all in this together, but it's really helpful to have someone who's just can work through all the same problems together.
Speaker 5:Yeah. And someone else, let me Josh and Adam both had 6 other day jobs they were doing. So they were like, yeah, Alan, that looks good. Whatever. And and when James were there, it was like, so many, we can read each other's code.
Speaker 5:We can, like, there's more, you know, we're much, we were much tighter collaborators there in that.
Speaker 1:And then and so when and then that that might lead that kinda leads us into RFD 177, which is the RFD that that you write, Wheel Tree also made public. And that get begins to get us into, like, what does this implementation actually look like and some of the actual implementation decisions that that we made there. Details. Yeah. Yeah.
Speaker 1:The details. And, I mean, as you were kind of getting into the details, what were some of the kind of the big important details or some of the the the important decision points in there?
Speaker 5:Well, I mean, I don't know if there's any anything new. The importance about keep it simple. Don't don't get crazy and make it work. And then, of course, for everything you're doing and every time you're doing anything, at any moment, you could lose power, and you have to come back. Now, I mean, that's always with storage.
Speaker 5:You always get into those. Like, the fast path when everything is working is kind of the easy part. It's all the damn errors, and it's all the Yeah. Every when this doesn't this message doesn't come back, and then you lose power, and then you come back up, but that one's not there. And it's like, it just explodes into complexity.
Speaker 5:And so working through all those of, like, a lot of the stuff we didn't see until we sort of stuck our foot into it, then you're not, you know
Speaker 1:And so how did I mean, you had the challenge that we all had of trying to develop this before we had a rack, so you're developing on kind of commodity hardware. Yep. But then you're also trying to to test many aspects of the system that are hard to test. So, how did what what was your approach to testing on all this?
Speaker 5:Well, again, Rust, makes it really easy to write these sort of unit tests that you can do, and you can I mean, it's it's sort it's kind of basic programming where you just kind of break it down into smaller and smaller pieces and then test each little sub piece on its own and then build back build back the more complicated system once you're, like, okay? I I know for sure this piece of it is is solid and, you know
Speaker 1:And then be and being able then to have kind of, robust testing also allows you to my to to move the implementation. It's sort of like, when I need to go make a change to the implementation, you can get some confidence.
Speaker 5:Yes. Yeah. That and then that's something, again, with with c, like, you never really know. Like, you hope, you pray. With with Rust, I have a lot more confidence that I I changed it.
Speaker 5:I mean, when you get to when it compiles, you're, like, pretty close. Still got to work out the logic bugs. But, like
Speaker 1:It is amazing how I mean, I think that this is where I I do feel that Rust really separates itself from, certainly, everything that I've used where that compilation, just getting it a big refactor to compile, you know, a lot about where you are. And I mean, so actually we kind of knowing that, that, that, that ability to for refactoring in the future, does does that kinda guide you in the present of, like, look, I know that, like, I can make decisions that are revisitable are are more readily revisitable than they may be in a c based system. Or if we need to to optimize this later or what have you. Like, I I I I can I can afford to, like, get the implementation right now, and then know that if we need to, like, improve the abstractions from a performance perspective, we can do that later? Did that kinda guide you at all?
Speaker 5:I want to make sure it works, and I want to build it, build the whole thing, build the whole stack, and then we can start iterating the different pieces. But, yeah, certainly knowing that we can come back and and update it later, give you the freedom to just, like, get the basic stuff working.
Speaker 1:And then how did I mean, you've obviously got a bunch of different failure modes that you've gotta be able to to test. You've gotta be able to I mean, disks coming and going and so on. How did you how do you simulate that? How did you test that?
Speaker 5:I, let's see. For me, personally, I we built some tools that that help us that will, like, do this sort of simulation where we all in one system, we can have an upstairs and 3 downstairs, all in different processes running and talking to each other, and then we built, like, a control system that will shut down different different parts of the downstairs and let it recover and see what happens. And so it gives us a lot of a lot of control, and then we built a a sort of fake front end where you can basically sit there as the upstairs and say, okay, now issue a right to this address, and then now read this address. And so you can, like, step your way through very specific sequences that allows us to replay things and to test a very specific you know, okay, I'm gonna take this one downstairs out, I'm gonna send a right. Then I'm gonna turn everybody off.
Speaker 5:Then I'm gonna turn them all back on and see what happens and, like, use all sorts of things like that.
Speaker 1:And then we and then you're able to do that in a way that is effectively automated, such that when when we go to improve the system, we can kind of check that as a as a did we regress this particular Yep. Condition, where where things are kinda transiently coming and going? Which I I mean, so important when, when you're endeavoring to do something like this. You really need to, to have and and folks in the chat are asking, well, did you use, you know, prop testing? Do you formal proofs, I would say, not quite formal proofs, but we, everything else is kinda in scope, and we we take kind of different approaches for different parts of the system.
Speaker 1:And we can definitely talk about 2 a plus. Someone's asking the chat. James, did you wanna talk a bit about testing?
Speaker 6:Yeah. Somebody had said, anything beyond unit test suite. Alan talked a bit about the, the testing tools, which I believe have the some of the best names at Oxide. We've got CRUD, which is the crucible DD that was written to test, you know, just basic stuff like that. We've got a couple of fun names there.
Speaker 6:But, just to sort of back it up a bit, I think it took, like, 5 minutes of of starting to work on the storage system. And and you sort of you understand, like, the mission is this has to work. Like, it has to be bulletproof. You can't lose customer data, stuff like that. So we've taken quite a lot of effort, throughout the year, 2 years, 3 years I've been here, in order to write these, you know, extensive tests.
Speaker 6:So we've got the the, the tools that Alan was talking about. We have, this this full integration test suite where we we have, Tokyo test that boot the downstairs and the upstairs and run various scenarios. We have the that also can boot, different, tools like our pantry service that, we also boot there. We have the my my favorite one of these dummy downstairs tests. I find that that can, tease out a lot of issues.
Speaker 6:We have a we boot a reel upstairs, but we talk to fake downstairs. And we can control, for example, like, this downstairs receives a message and then goes away while the other ones receive and and answer their messages, then it gets kicked out. For example, it comes back. We make sure that the upstairs is either replaying or or reconciling and repairing. You can have very, very fine grained, downstairs behavior based testing in that case.
Speaker 6:And this is all done, through the, through the API. So, yeah, I, you know, lines of code are a terrible measure for for this kind of thing. But I think we've got quite quite a few, almost, I think, parity of lines of code to lines of test code. And I know that, you know, that's that's what it is. But, yeah.
Speaker 5:Because we're all measured in, you know, our progress should be Yes. Gives us just by lines of code we do per week.
Speaker 1:Yeah. That that's exactly right. I have found that that it creates no perversions and it's and it would just like to stack rank the organization by lines of code per week. I
Speaker 6:found that. Exactly. Yeah. Yeah. I think that's Very early on, I understood that I had to game the system like this.
Speaker 6:So every PR has, you know, 12,000 lines of testing code, you know. Yeah.
Speaker 4:The most important measure of a software system is its mass for all.
Speaker 1:That's exactly right. That that's what we have written up on the wall here. And when in this testing the the testing framework became really, really important when it became it's like, okay. This thing works, And now, like, we let's make it faster. And, Matt, this gonna be a good opportunity to get to get you in the conversation here because you've been very much on the the the forefront of of making it faster.
Speaker 1:Because we had we we had us I mean, and I mean, to a huge way to Crucible's credit, it's been great. It's, it's done what it's needed to do in terms of, like, you have we have haven't even had data. We'll take vacations like that. It's it's been great. But, we also need to make I mean, there is no one of the challenges with IO is, like, there's no performance that is gonna be a we always want more performance, and you always wanna be able to do, the the absolute most amount of work.
Speaker 1:And, Matt, maybe you can describe some of your early work, and and, I think this is where also the the presence of the test suite, the chemical partition rust becomes super important when it comes to make it faster because you can actually make some pretty radical changes and get some confidence in them.
Speaker 2:Yeah. Absolutely. I mean, if Alan was coming in at, like, from the bottom up and James was coming in from the top down, I guess that leaves me at the, like, middle out position. So, yeah, I joined the Crucible team, I was previously doing Hubris stuff, working on embedded switch firmware. I was on a previous episode about that a while ago.
Speaker 2:But I joined Crucible and started working in earnest, August of last year and was kind of the mandate was basically like, look at things that are slow and see if you can make them faster. And so this was another situation where, like Brian said, like, using Rust, having such an extensive test suite meant that we could do relatively broad refactoring. One of the things that we changed relatively early on was the actual on disk format that we use for data, where this is going a little bit into the weeds, but we are using authenticated encryption. So we have to store both a blob of data, which is like 4 k, for each block, and then an associated tag and some metadata for the encryption. And you can't mess that up.
Speaker 2:If you write the block but don't have the metadata, then you're not gonna be able to decrypt it. And so you the implementation that we had previously was actually using SQLite to store the metadata because that's something that is very good at not losing your data, and it would actually store, like, multiple rows of metadata and then when it loaded, it would pick whichever row corresponded to the block on disk and use that. And so one of the things we worked out is that we didn't actually quite need that level of overkill. We could actually store the metadata within the same files and we started leaning on, like, some ZFS behavior where if you're writing the the same file descriptor, then you have certain guarantees about ordering and what's persistent on disk based on when you send flushes. So changing from or changing from SQLite to just using raw files is like a 30 ish percent speed up for a bunch of small writes, and so that's kind of an example of like, there's a lot of, we're pretty far from the raw speed of disk IO and we've been slowly bringing it closer and closer through both like micro things like that and, like, bigger architecture changes and kind of refactoring large chunks of the system to do async more efficiently.
Speaker 4:Do you remember when we checked SQLite back out though, like, I feel like it has to get some kind of special mention for being really quite a lot faster than even I expected. I think that it was gonna go, but it lost. It lasted quite a while. Yeah. It was pretty impressively quick.
Speaker 5:And we didn't have it originally. And then we put it in and then.
Speaker 4:Right. Because we didn't have we didn't have we had naively in 2020, not really thought that hard about encryption and what it meant, and the, the property of like the, like unauthenticated encryption can be, size preserving. So if you're going to write a 4 k block and then or an encrypted version of that block, it's still 4 k at the end. But the authenticated encryption stuff, which unfortunately like is unfortunately necessary. Like when you look at all the attack models, it's like kind of difficult to argue that it's not necessary.
Speaker 4:And it just like it adds some number of additional not very power of 2 shaped data alongside the 4 ks sector. It's gonna be like 4.1 ks, which doesn't fit very good into anything.
Speaker 2:Yeah. It's a 48 bytes of metadata.
Speaker 4:Right. Which is like, you think, oh, that's not much. It's like, well, it's not, but also it's not a multiple of anything. It has to go you have to like atomically update that 48 bytes alongside the block data which is nicely shaped on purpose. So that definitely made it a lot more complicated and that's why we ended up with SQLite.
Speaker 4:Whereas in the original model, we didn't have any of that metadata stuff hanging off the side. We just had like a flat file basically. But, yeah, it probably makes things challenging.
Speaker 2:The funny thing about SQLite is that we actually tested 2 versions. In one version, we got rid of SQLite and put everything into these raw files. And in the other test, we got rid of the raw files and actually put the block data into SQLite. And both of those were actually faster, but we decided to ditch SQLite for this for the sake of simplicity, but it was still pretty impressive.
Speaker 1:Yeah. Well yeah. And I mean, it was actually I mean, SQLite is just kind of what it says on the 10th. It's very robust, and it was actually pretty easy to understand what was going on. Relatively easy to to to instrument the system to understand what's going on.
Speaker 1:And, and, Matt, you're kinda, it's in terms of some of the bigger refactorings. I mean and we've made available, RFP 444 and 4 45 go into some of the things that we that that you've worked on there. What were some of the the ways in which we were able to kind of refactor it to, in the name of performance?
Speaker 2:So RFD 444 is a deep dive into the upstairs architecture and kind of a big refactoring, probably too big, that switched a lot of the data ownership around. Where when the software was growing it was using Tokyo Tasks to do a bunch of different operations in parallel, but those tasks were all mostly operating on the same chunk of data. Like, we had one big lock where each task would lock it and do some work and then unlock it, which meant that you weren't actually running the tasks in parallel, like, you weren't actually getting much parallelism out, and there were also concerns of, like, well, are you sure that you maintained your invariance correctly? And are you sure that the locks live long enough that no one else can interrupt you? And stuff like that.
Speaker 2:So rfd 444 describes a relatively major refactoring where we took the system of, like, 6 or 7 interlocking tasks and basically refactored into one big task that owned all the data, and then a handful of smaller tasks who were just doing serialization, deserialization, and encryption at the edges. And that ended up being a decent speed up because we could kind of figure out where is the heavy work, which was again encryption, serialization, deserialization, and then move that out to the side. And the simple, you know, quote unquote simple logic of just shuffling what jobs are ready to run and kind of throwing them over the fence to the different downstairs, that could all be done in one place which owned all of its data. So that ended up being another nice speed up.
Speaker 1:And, you know, Alan, you were talking earlier about not being able to imagine doing it in c. This refactor is one where, like, I cannot imagine.
Speaker 5:Yeah.
Speaker 1:This is because this is the kind of thing where I don't care how veteran you are with c. Like, we're now gonna really kinda change the way things are paralyzed and and or not and just, like, would be very hard to get confidence in. And I think this was a huge I mean, the the fact that we could do this kind of refactoring, it all let alone get, like, pretty quick confidence
Speaker 6:in it.
Speaker 3:Another good example
Speaker 2:of that is actually, like, a smaller thing, which I've I've mentioned this to everyone at work, but I recently went through and just removed 4 mutexes from the crucible downstairs because they were not actually protecting anything. And that's the kind of thing where if I was doing this or c or c plus plus, I would be terrified to make that kind of change because, like, we never know how to stash a copy of your data.
Speaker 4:How would you know?
Speaker 2:Yeah. But because we're using Rust, like, I tried compiling it. I had to add a couple of more, I had to make a couple more ref, things mutable instead of immutable. And there was one thing which actually the compiler was like, hey. You're secretly sharing this between threads.
Speaker 2:So I had to re add 1 mutex, but I still got rid of the other 4. And then once it compiled, it was like, hey, I'm pretty sure this is safe.
Speaker 4:In the original sketch of the whole thing, which was not more than a couple of 1,000 lines really, like, I had absolutely punted on any hint of performance, like in the job tracking stuff, like the because my expectation was that we'd be able to fix it later, basically. Like, I had really focused on the correctness, which I had achieved through a lot of things that did a lot of loops, scanning over everything. And rather than like having a list of tasks that are in this state and a list of tasks that are in that state, we just put them all in one big list and we had a state variable on the task. And I feel like one of the first performance things, maybe Brian you worked on was like refactoring some of that stuff so that we weren't doing as many scans of memory to, like once we'd figured out what shape the data structures actually needed to be in to track these things and what what properties we needed to enforce as invariants across the whole thing. Like I feel like it's been there's just been a lot of constant refactoring as we've unpicked experiments and turned them from, like, a correct proof of concept into a correct and fast operable system.
Speaker 1:Yes. Which is, by the way, that's the same path that ZFS itself took. Right? ZFS itself. But, I mean, if you the the I mean, Adam, when you describe us shipping that in 2008 and that kind of being even though ZFS had been in customer since 2005, the the difference between what we did from 2,008, 2,009, 2010 was really all ultimately around performance and it's not performance in kind of the way you might think of just, like, IOPS because performance is a lot more than just IOPS.
Speaker 1:Performance is how do you behave when things begin to to behave pathologically, and, I feel like, you know, Josh, what you're describing where you have things that that scale with the data size, in particular, like snapshot deletion, was a I mean, the one that definitely has some scar tissue, where ZFS would do these where a small snapshot delete would be fine, but a large snapshot deletion would be on the order of the you you end up in when you're trying to sync a transaction, you're doing random reads, which is always the kiss of death. And, you know, Matt, Aaron's some terrific work to to get that out, and be able to do large snapshot deletion. And I all also think that, like, one of the challenges too is that, and this is, I frankly, one of the advantages that Crystal has over CFS is the ability to do these kind of refractors, because some of these refractors were were really impossible in c I mean, there's some refractors that I think would just be really scary to do in CFS because of the way state is spread through the system. And I mean, we, like, we had dedupe, for example, ZFS supports deduplication, but the way it was done was definitely not very many lines of code, but really problematic from a performance perspective and not really possible to ride the ship on that one, That one's it's gonna be I wrote I wrote the dialogue box though that you have to click when you want to enable it.
Speaker 1:Be real explicit about that.
Speaker 6:One of
Speaker 2:the other funny things that we ran into with these cleanups is we had a lot of sources of what we started calling accidental back pressure, like things that scaled with the number of jobs in a queue or scaled with the size of writes. And as we started taking these down, we suddenly ran into issues like, oh, look, the upstairs is gonna buffer 400 gigabytes of rights because there's nothing slowing it down anymore, and the downstairs cannot keep up.
Speaker 1:So the with now let's talk a little bit about back pressure because back pressure is very, very important. And, I mean, if you do not develop deliberate back pressure into your distributed system, god will develop it for you. And he's
Speaker 4:not he does not wanna It doesn't even need to be distributed. Right? Like, I mean
Speaker 1:It's true. A lot
Speaker 4:of these a lot of these surprise explosion bucket things were like like between queues were were just inside the process.
Speaker 1:God's own back pressure is not pretty. You do not want that one. You want that you want the designed one.
Speaker 3:Well, it's worth saying, I mean, in particular, God's own back pressure becomes very inconsistent and unpredictable. So there's always going to be back pressure somewhere, but it's sort of what it looks like.
Speaker 1:Well, and god's own back pressure actually manifests itself as a date of vacation. It's like we are this system is no longer available and will be available when when it is chosen to become available again. And that's not what we want. We wanna have a not to not to play too much divine intervention in storage systems, but it sometimes feels that way. Although I actually didn't learn you know, Don McCaskill was an early customer of ours, Adam, at at Sun.
Speaker 1:And every time I think of Don McCaskill, all I think about is waiting for his data to come back on a Zebra import that was taking, like, 45 minutes. And he doesn't even remember that happening. God bless him. So, you know, sometimes he doesn't remember the vacations, but, it was very painful. So you Matt, how did you kind of think about back pressure in the in system?
Speaker 1:In terms of designing it explicitly.
Speaker 2:Yeah. So it's interesting because things like reads and flushes, we had to wait for the downstairs the upstairs submits a write, we immediately tell it you're good! Because writes don't need to be persistent until the following flush actually comes along. And so this is interesting because it's analogous to, actually an old blog post from Adam, one Adam Levinthal about the ZFS right throttle, which is solving basically the same problem of, like, we can cache a certain amount of data in RAM, but we can't cache infinite data in RAM, right? So we have to start slowing down at some point.
Speaker 2:So the design, I can't remember whether I came up with it before or after reading that blog post, but it ended up being very similar where we track a handful of things, like we track the number of jobs that are in flight and the number of bytes that are in flight, and we have a quadratic equation with a bunch of tuning parameters that I made up at random, and that will artificially delay writes, So the system ends up ends up in a kind of steady state where the delay added by this backpressure converges to the same amount of time it actually takes for a write to go through the whole whole system. And that is, like, pretty good. There's still some tuning that we need to do that rfd 445 talks about a little bit, but this fixed the, like, most pathological case of the upstairs will buffer infinitely many infinitely much right data because it's so much faster than the downstairs.
Speaker 1:Yeah. I'm pretty sure the the infinite buffering was due to was due to me. Just due to me or Alan, I think is that is that a fair,
Speaker 5:you may have suggested that You're
Speaker 4:the you I remember you you came to seek an indulgence about this. Right? You're like, couldn't we just I think you come to seek an indulgence about this. Because we used to, you know, foolishly wait for wait for 2 of the rights to be acknowledged on the platter basically before we would
Speaker 5:Oh, yes.
Speaker 4:Before we would tell the guest. And it's like, we don't actually need to do that. That's true. It did go quite a lot faster. We stopped waiting for that.
Speaker 3:Oh, yeah. It's
Speaker 4:fast enough fast enough to explode, in fact, as it turns out, like
Speaker 1:And and so just to give folks a little bit more of additional context. So the we are we are presenting a virtual block device up to a guest, and we are telling the virtual block device that, hey, by the way, we have a right cache. There's a write cache that's enabled on this.
Speaker 4:A a non non volatile? A non volatile write cache or a volatile one?
Speaker 1:The volatile one. So the
Speaker 4:the Volatile one.
Speaker 1:Yeah. So if you have if you've not done if you've not done a flush, you cannot assume that that your that your data has been persisted. So the but we were on rights. We were waiting until those rights have been acknowledged by 2 different machines because it's like, well, I mean, like, what are we? Nuts?
Speaker 1:Like, of course, we wanna make sure that 2 different machines at least have seen this thing and have have synced this out. And I'm like, well, hey. We can make the system go a lot faster. We just, like, we just can act it immediately, of course, that That's what
Speaker 5:the disk is doing. That's what your argument was. Like, that's the disk is doing that to us already. Why don't we just pass that on to the
Speaker 1:the And what can go wrong? I'm sure I said many times. But, yes, I was seeking indulgence. It turns out that created sorry, created a lot rather, explosive amount of now we've we we have now can explode the upstairs with buffer data, which is like, that's so good. So we've gotta actually and it it's always kinda paradoxical to me when you actually need to make in order to make the system go faster, you need to throttle the work.
Speaker 1:You know, but this is like the, you know, these are the metering lights in traffic. Right? I mean, it's like, in order to be able to to make the aggregate system go faster, it's like, yes, you need to stop your car right now. Like, the fact the way to make to get you to work quickly is to be to have you be stopped right now, which can be very counterintuitive. But
Speaker 5:And the I mean, the back we knew we would need to do the back pressure work at some point anyway. There were lots of, like, come back and do this better next time comments.
Speaker 1:So Well and and I think, importantly, I mean, because you you were were constantly picking and choosing about, like, what is the stuff that has to be exactly right out of the gate versus what are some implementation and implement the implementation artifacts we can improve. And, I mean, we had to get the reliability. Obviously, it had to be correct, Alan. Yep. What were some of the other things?
Speaker 1:Because we we encryption was an important constraint.
Speaker 5:Yeah. Making sure I think Josh talked about this earlier, that the order of things happens on all 3 of the all the downstairs in the same way. So whenever the IOs land, they all got to land in the same way. That's another piece that's sort of fundamental to the whole the whole thing working when you come back up after a power loss.
Speaker 1:And then so and those are the things that that absolutely and then there's a bunch of functionality that you also, like, absolutely need. Like, snapshots are not really I mean, are are rather important for us.
Speaker 5:Yep.
Speaker 1:James, can you talk about the development of that in particular? Because as I recall, you know, in software, most things take longer than you think to do. And every once in a while, you have something that is actually faster than you thought it would be. I feel like, Matt, this giant refactoring that you, I I feel like that's an example even though as big as that was, the fact that that was possible at all, let alone the speed at which you're able to do that and get that integrated, I think it was actually faster than one would expect. And, James, it felt like that way for some of the snapshot work you did well.
Speaker 1:Am I recalling that correctly? There were some I just recall you wake like
Speaker 5:When James did the volume layer, I think that opened up a whole bunch of doors and solved a bunch of problems that we were like, I don't know. We'll get to that later, hopefully.
Speaker 1:So, James, do you wanna elaborate a little bit on that on on the volume layer?
Speaker 6:Sure. Yeah. I had to look this up. I'm not great with dates. So early 2022, we had a storage huddle where we talked about kind of what what Alan had said.
Speaker 6:So, like, hey. There's all these things that customers are going to expect from our cloud. We should probably, start thinking about that. So that was Monday. Right?
Speaker 6:And so I came out of that. We start start thinking about it. At that point, we had Propellus with its NVMe device emulation that would, underneath that, talk to what we called the guest. Now this would be the object that communicates with the upstairs through, channels. So when the when there's an NVMe read that comes in, this gets turned into a crucible read, sent over this channel to the upstairs.
Speaker 6:The guest memory, and then the NVMe doorbell gets wrong, stuff like that. But the structure of it was, this guest object, and that was implementing all the things you would expect, read, write, and flush. We had, so we had Propellus. So start I started thinking about, what that product had to support based on what was in that meeting. So booting from a image of some sort, you would you know, everybody shares the same Ubuntu server image, for example, and you would have to spin up a VM from that.
Speaker 6:Snapshots, taking that from the disk, and then booting from those snapshots, stuff like that. But then some of the more, like, elastic properties I expect, like, growing a disk, for example, at runtime, stuff like that. So take booting from take booting from, an image as an example. Say a user wants to boot a VM. They create a 32 gig disk, backed by an image.
Speaker 6:Let's take that Ubuntu Server image. They click Start VM. We didn't want to have customers wait, you know, for us to copy all the blocks from an image into this freshly allocated 32 gig, blank region and then boot the VM. You know, that would be not a great experience. So out of that, you you think, well, now blocks have to optionally come from different sources.
Speaker 6:And this was, you know, never in the and never in the design of the northern, you know, the southern monks who's never in the design of the upstairs and the downstairs. These this optional location. So breaking it down for, you know, an image base, you're booting off of an image. The images blocks the image blocks have to come from somewhere immutable. Right?
Speaker 6:You don't want the the guest to be able to alter those. But any write should go to this freshly allocated 32 gig region. And then the other thing you have to make sure that, subsequent reads of of those written blocks would come from there. I think at that point, yeah, at that point, we could tell if a block had been written to based on the existence of this block context. So if you've got the either the encryption context or the integrity hash that we store alongside, the encrypted block data, you know that a write had occurred.
Speaker 6:So we could use that at least to to say, you know, the allocated freshly 32, you know, 32 gig region had it right there, serve that, else serve the image block. But then you have to think about layering. Right? So you could teach an upstairs to pick from 2 sources optionally, like, depending on, you know, which which right shadow each other or not. But say a user has a disk, and then they say, k.
Speaker 6:I'm gonna take a snapshot of that disk. And then I'm gonna boot a disk based on that snapshot, and then I'm gonna know. It takes a snapshot, blah blah blah. You say they do this a 100 times. Now your blocks have to come from an arbitrary number of places.
Speaker 6:I didn't want to, you know, muck with the upstairs that much, right? It's doing a lot of complicated things, wrangling the the 3 downstairs. And I didn't want to have an arbitrarily large list of these block sources, right? You only want to deal with the 3 mirrors. We know, up until that point, all the code that we had written, was doing that assumption of 3 mirrors.
Speaker 6:That was something we were comfortable with. And importantly from Propellus' perspective, whatever we came up with, it still had to just have that interface of read, write, flush. Propellus shouldn't have to do any special work here. They just, you know, talk to the the blocked dev layer, as it were. So in thinking about this, this layering problem, and at the same time thinking about how, Propellus shouldn't have to care, I came up with the idea for the this at the same time, you come up with the idea for the volume hierarchy.
Speaker 6:You come up with the, Block IO trait. So I took what the guest, was already doing and turned that into a trait that that called the block IO trait. So
Speaker 1:And and and a trait in the rough sense, to speak with.
Speaker 6:In the rough sense. Yeah. I was very much inspired by, by how awesome Russ is. Yeah. Which was also referenced in the demo, which we'll get to that in a sec.
Speaker 6:The yeah. So read, write, and flush, you get block size, you know, stuff like that. Guest already implemented all of this. So then this, volume implementation, so the volume object came about. So this is a struct that itself implements block IO.
Speaker 6:It has an optional read only parent and then a list of what are called sub volumes, which have which themselves implement Block IO but also store LBA related information, so logical block address, so a range of some sort. And, from this, you have that that sort of model where writes go to the sub volumes and reads can come from either the sub volumes or the read only parent, depending on if a block was written to or not. And then you have this immutability by saying that writes only ever go to the sub volume. And volume the volume layer takes care of all the you know, you have to split a read and send you know, certain block reads go here. Certain block reads go there.
Speaker 6:The splitting the rights also accordingly. Flushes go everywhere, because, you know, you have to flush everything. So so after that, you think, how do how do we solve this layering problem? Well, the volume object implements block IO, so it can itself be a read only parent. And then that gives us that that layering right away.
Speaker 6:So in the case of a, take a snapshot, for example. You have a read only parent, which is a image source of some sort, and then the freshly allocated 32 gig region. To take a snapshot is to, first of all, perform a ZFS snapshot on that 32 gig region. This gives you places where you can boot read only downstairs out of the dotzfs/snapshot directory. And you know based on ZedFS's guarantee that this data will will never change.
Speaker 1:So this is actually an important point, James. And I just would because, you know, we didn't really belabor it, Adam, when we were talking earlier, but someone might reasonably be like, wait a minute. You're gonna have a z pool that consists of a single SSD. You're gonna have all these, you know, 10 NDME SSDs. Like, are you putting a Zpool on them?
Speaker 1:Like, just use the device directly. And there I mean, there was a bunch oh, there are a bunch of reasons for it, but we wanted to be able to leverage a bunch of the semantics that ZFS was offering, even though we weren't using erasure encoding or mirroring.
Speaker 4:You wanted the copyright snapshotting stuff. Like, you
Speaker 1:want the copyright snapshotting stuff.
Speaker 3:And you want to make
Speaker 4:certain things, like, really a lot easier. You don't have to invent or contort your data format into something that does its own native copyright stuff. Like you can just write the files and take a snapshot at the time that you need it and and then access it as a read only thing off to the side. It's pretty good.
Speaker 1:Right. So really it's so sorry, James. Just just to briefly interject in terms of, like, why that because when you're developing the snapshot mechanism, you're you're able to leverage, You're able to at least solve some fraction of the problem, by using ZFS snapshots.
Speaker 6:We end we ended up relying on a few of those ZFS based things for, at least the sort of the raw extent work, and, some of the guarantees that we get about, the downstairs will only ever return, for example, okay if if, you know, all the check sums from ZedFS say that they're okay, you know, for example, stuff like that. Yeah. We we end up relying on it. Copy on write and the transaction group stuff. Yeah.
Speaker 6:Yeah. So Sorry. Yeah. So all of yeah. All these problems that, I think I was there.
Speaker 6:All the problems that we had talked about in that storage huddle, growing a disk, well, that's just, that's just adding to the sub volume like, the the the VEC of sub volumes. You can even talk about, re encryption. So you you make the existing volume a read only parent, and then you boot a equivalently sized, region with a different encryption key. Importantly, you need this operation called a scrub, that is done, by PROPOLIS, where blocks are read from the read only parent and written to the subvolume, but only if they had never been written before. So this is not going to overwrite, what the guest whatever guest activity had occurred.
Speaker 6:Once that once something like that is done, you can drop the read only parent, and then issue all of your reads and writes directly to the sub volumes. You could even do a crucible upgrade, right? Like an upstairs V2 or or something like that because this is all hidden behind that that trait. It ends up being a a hammer where everything that that we wanted to, to solve would be the nail, I guess, in this case. So, Brian, you're not wrong.
Speaker 6:It did come together very, very quickly. It was Monday was was sort of the genesis of it, and then Friday was the demo. I remember, talking to, you know, Alan for feedback during the week, but there was a particular meeting on, Thursday where it's like, oh, yeah. This came together. But is this good?
Speaker 6:Like, what do you think? I had it with, Josh and and Alan. I was like, hey, what do you think? Did I miss something? Did, you know, did did I overlook something?
Speaker 6:It'll bite us later kind of thing. I was pretty excited. I wanted to sort of demo it and, and sort of start building on top of it, because it enabled us to, to move in that direction pretty quickly.
Speaker 4:I think the the, the stuff that you put together with that abstraction really, was like a good, like concrete rendition of a bunch of hand waving we'd been doing for probably 2 years at that point. Because we, we had talked a lot about, the fish works appliance had had a feature called shadow migration, I
Speaker 1:believe. Yeah. Yeah. Yeah.
Speaker 4:In which in which, like, you would say, all right, you got this existing file server with, you know, 100 gigabytes of crap in it or whatever, or terabyte or something. It's gonna take a while to copy that over to this new shiny file server. So instead of just everybody has to unmount everything and go away for 8 hours or something, we would, you would just mount the new thing directly and the new thing would be smart enough to fish old files out on demand from the back end and copy them into the front end before serving them up. And then it's almost a little bit like hierarchical storage management. Like, I think we had talked at some length about how that was gonna be the thing that we were gonna do for all kinds of things we didn't wanna solve at the time, like, rekeying, migrating data format to data format, upgrading software, stuff like that.
Speaker 4:And then when Jamies put this thing together, it was immediately apparent that it was going to be useful for All
Speaker 1:sorts of stuff.
Speaker 4:All sorts of stuff. And then, like, pretty concretely demonstratable in a very short order. It was it was, it was a big win for us.
Speaker 1:I I mean, there there have been a couple of demos that have blown me away over the history of the company, but that is definitely that is among them where it's just like changes. It felt like that demo was like, but wait, there's more. But wait. There's more. But wait.
Speaker 1:There's more.
Speaker 5:That was the n f yeah. NFTs involved in that demo, I believe.
Speaker 1:Right. Is that the word? The, I definitely remember well, I've learned that, like, part of the problem is that there is, there's an inner performance artist apparently in every oxide engineer. And, James, your demo with Greg that you alluded to earlier when the 2 of you were playing Minecraft using the oxide, rack, I learned that I could never trust again because you 2 were that there was so so much was part of the bit. And, like, whenever Matt's giving a demo, like, you'll then really feel at the end that, like, you're actually all in my demo right now, which I feel happened at least once, Matt.
Speaker 3:So
Speaker 2:that that's the time that I was demoing the network switch and actually running my demo Internet through it. But the problem with this is that now whenever anything goes wrong during a demo, everyone is like, is this a bit? Is this a bit? I think this is a bit.
Speaker 4:Right. And
Speaker 1:it it often is. I feel I feel like it's it was James, it was that that demo was amazing. It's not how much came together, how quickly. And, I mean, it's you know, I always tell people, like, when whenever that happens, man, just make sure you bottle it up so you can spray it on yourself later when something seemingly simple is taking you. Like, this is taking me much longer than I thought it would take, which feels like it's much more common in software.
Speaker 1:But that that must have been, James, James, that must have been a great feeling to have that come together so quickly.
Speaker 6:That that was a fun demo. Yeah. I I so I actually I had remembered something, and I don't know if any of you also remember this. So I looked at that demo again because, at one point, I had a slide with with the sort of the volume struct. And I was like, here it is.
Speaker 6:You know, it's just a couple of fields, blah blah blah. But I I didn't mention this during the time, but it didn't say, you know, like, read only parent colon arc guest. Right? It said dine block IO. I didn't mention at the time, but later on, as a slide, I I referenced back to it after the first part of the demo.
Speaker 6:And I said, you know, eagle eyed readers would have noticed that it didn't say guest. It said, Blacayo. And Matt in in the chat said, actually, yes, I I did notice this, which, which is kinda fun. He's before the the days where he had joined the team and and sort of done the work, he was already saying, like, this is yeah. Anyway Eagle eyed in the
Speaker 1:in the demo. Really an eagle eyed. Well, it was I it was that was great to great to see. And I also felt like it was one of those and I think there have been, again, a couple of these where whenever you're doing something hard and long, you're kinda looking for good omens of, like, okay. We got like, we're we're like, we're seeing a seabird.
Speaker 1:We're headed towards land. You know? We're not gonna be out here forever. And I I don't know, James. I felt like that was one of those good omens.
Speaker 1:It's like, okay. We've got we're we're got some things that are actually going in the right direction here. Some things that are structured the right way where you can make a change like this and have some stuff come together. I mean, that one must have felt that way to you.
Speaker 5:Yeah. Well, it was like this maybe this thing really is gonna work.
Speaker 1:Might actually pull this off. Yeah. That was that was great. And we've been able to build a lot of functionality on that. I mean, that is that that feels like that has been a James, that has stayed a a good abstraction and really important because, as you say, like, when you're spinning up guests, it's like snapshots writable snapshots become actually not some esoteric feature that's nice to have, but, like, actually acquired or any real use of the rack.
Speaker 6:Yeah, it's one of the, yeah, one of the thing killer features I would say, like, of cloud based infrastructure like Snapshot, You know, we don't have it yet, but, like, Snapshot restore, for example, exporting, importing, stuff like that, like, these sort of virtual storage things that you would expect. Yet because we're using ZFS snapshots, for example, we can do this very, very quickly, and and sort of build on top of that by booting another disk. And and, you know, our control plane takes care of all the reference counting and, cleaning up the objects when when done, if there's no longer, you know, dangling, you know, volume layer that points to it. It's been it's been pretty good. Yeah.
Speaker 1:So, Alan, what would have been some of the the surprises along the way in terms of the, I mean, are are there things that have been surprisingly hard, surprisingly easy? I mean, I I would think you you always, with with storage, it's always at the margins. And in terms of, like, the degree that misbehavior deep in the stack can cause, kinda outsized effects of the stack. But what what are been some of the things that stick out to you?
Speaker 5:Hey. I know I know that I had a lot of trouble with the live repair, figuring out how that was gonna fit in it into the whole big picture. That took me a while to sort of get that sorted.
Speaker 1:And so describe the constraints a bit on live repair.
Speaker 5:That's when you're you're taking IO from the the guest, from a VM, but one of your downstairs has failed, and you have to you have to fix it. You have to make it consistent with the other 2, but you you can't just take a long vacation. You have to do this while new IOs are streaming in. I mean, it it's not a not a new problem. Anyone who's been raid, reselling has figured it out, but it's just in the scope of our distributed it at any moment, anything can disappear.
Speaker 5:Everything can disappear, and then the power can go out and all that. That was certainly a challenging piece of work.
Speaker 1:And and that was I mean, that was something that came together, like, relative I mean, that was that came together in come together. I think it was about early 23, early last year. Am I am I remembering that correctly? Maybe it was late 2022.
Speaker 5:Yeah. I think it was early 2023.
Speaker 1:But one of those things that was required to ship. That way, and, I mean, so much was required. We had to run the table on on so many things because because this is the kind of thing. I mean, we say this about, like, all sorts of aspects of the system, but if this doesn't work, you don't have a product. Like like, you need this startup to actually this startup within the startup has to actually nail it, like every other startup within the startup.
Speaker 5:Oh, I mean, I don't know. I think pretty much everybody is working on some piece that is completely, totally required. It's not like anybody else wasn't working on something that was also critical. But, yeah, this was another of the 55 pieces that had to absolutely work,
Speaker 4:it was
Speaker 5:one of them.
Speaker 1:It's like as I told people we're gonna ship the rack. Like, if if you have the feeling, like, boy, what were they gonna do without me? They would have been screwed. It's like, yes, we would have been screwed, and we definitely would have been screwed, without, without all of you, without and and all of the the the hard work that went into all aspects of this. And it's been I actually, describe also, when did we open up a crucible?
Speaker 1:When did that happen? Because this is all open source, which should be said. Yeah. Folks can go and kinda check out the repo and
Speaker 3:It might I may be misremembering, but I think this is one of those ones that we open sourced out of convenience. Like, it was I
Speaker 1:don't know.
Speaker 3:Pain in the neck.
Speaker 1:Well, can you can you it might have been a pain in the neck. We open source Propellus because, Patrick was interviewing a candidate and wanted to be able to talk about it. It's like, I wanna be able to talk with Propellus in 45 minutes. So can we open it? I'm like,
Speaker 2:sure. Open source Crucible because we use it as a dependency in Propellus. That's right. Easier to use a Git dependency.
Speaker 3:That's right. It was it was purely the convenience of Git dependencies.
Speaker 5:Yeah. Yeah. 75% of it at least.
Speaker 1:Yeah. It is a real pain in the butt to have things that are like some things are public and some things that are private. So, yeah, I think we that that is, plenty of the things we've opened a bit because of that. And so we we so we got that out there, I guess, a while ago, but, I was gonna go check that out as well. I'm I'm not, not sure how, readily deployable it will be.
Speaker 1:They're all, like, plenty of of dependent. But honestly, it's a it's a pretty well contained unit too. So it does actually
Speaker 5:Yeah. I mean, I I develop on a Mac, and I run it locally on my Mac just for itself. And it, you know, compiles there.
Speaker 1:And I know, like, Artemus and I have been doing a bunch I I mean, we were both going in to do, some of that early performance work and kinda going into a foreign source base, and it was it was good to be able to, I mean, the source base itself was very approachable, I gotta say. Very it it did not feel, you know, complicated systems can be very complicated, but, you know, it was always pretty clean to figure out what was going on here and and I think clean before and after the big the the great refactor, which is, made it easy to add to kinda add people to the source base as well. Right. So what's the future? I mean, we got I think it's done.
Speaker 1:Right, Ron? On on other things. I'm sure.
Speaker 4:I mean, you're the you're the boss. So
Speaker 1:I I I noticed you, like, practically muted yourself while saying that. You you couldn't find yourself
Speaker 4:I actually fell forward something.
Speaker 1:You could. You fell forward nothing. You you you you replied when you said that, Josh.
Speaker 4:Try to contain myself and apologize.
Speaker 1:Right. Well, I mean, we still I mean, there is, and, James, I know you alluded to some of the future work, but there there is always so much to be done. I mean, I think we've got we we we have what we needed certainly to ship, and we've got thanks to, Matt, your work, we've got, and everyone's, really, we've got a the system that is kinda performing better every day. And it's been fun to deliver upgrades to customers and just like, hey. Your short performance is just getting better, is is pretty exhilarating.
Speaker 1:And
Speaker 5:you still get your data.
Speaker 1:Yeah. And, yeah, what a bonus. Your data is still here. So I think it's been really I broadly, I feel it's been really successful. We've been able to do exactly what we wanted to go do.
Speaker 5:And
Speaker 1:I think we got a great foundation to go to go build upon because we're gonna have we're gonna be building upon this foundation in crucible forever, effectively. Mhmm. And we this is gonna be the way, you know, with whenever VMs are deployed, like, this is where the root file system is gonna come from, and it's gotta be exactly correct. And I think and really terrific job on it. It's been fun.
Speaker 3:No. It's a it's I I think storage is one of these things. Like, there will be no end. Right? There's always not just on the current iteration, but, like, there's you know, every new customer requirement, every new workload creates like some whole new, subbranch of either how we're thinking about the current system or plans for the next system.
Speaker 3:So, I mean, James, Allen, Matt, this is not to say your last to the mass forever, but just as long as you want to be.
Speaker 5:We
Speaker 1:got plenty of work to do. That's for sure. Yeah. Yeah. Yeah.
Speaker 1:Alan, any, any any closing thoughts on James, Matt?
Speaker 5:It's been a great it's been a great whole team to work with and and the company, you know, having a blast.
Speaker 2:Yeah. I could not have picked a better, you know, multi many thousand line of code base to be plunged into on short notice. It was great.
Speaker 1:You asked I well, sound like you're speaking under duress. You know, I'd like to Josh, do you have anything you'd like to say now that you've heard that
Speaker 4:you've changed? Blinking.
Speaker 1:Exactly. A prime number
Speaker 4:of times now to to communicate.
Speaker 1:Please read your prepared statement that I've asked you to give.
Speaker 6:Yeah. And this team is the yeah. Exactly.
Speaker 1:And fun. Has been fun getting better every day, and I definitely welcome folks to check out the RFTs, learn more about what Oh, I will,
Speaker 4:I will say that it it, I think, like if you think about crucible as a narrative arc, like really one of the most important things we did was hiring.
Speaker 1:Yes.
Speaker 4:Which I think is like always the most important thing we did. But like but like it really, I think needs to be emphasized that like, you know, when when Alan came on and then James, like, we as Alan noted, we're doing 6 other things, and it was really not the focus And it was not gonna happen without some people for whom it was more a dedicated focus, and and we did extremely well with the king. We're very fortunate to have Alan and James lash themselves to the mast.
Speaker 1:Ross, I think a testament to that, and I also do think I mean, you kinda have heard it kinda heard us weave it in here, but it's been a big testament to Russ too. Because I think it's been the the fact that we've been able, I mean, to have Matt join the code base, you know, relatively late in his life after we've after we deployed it to our first customers and be able to, like, really,
Speaker 5:use some pretty serious rototiller. Some
Speaker 1:one of
Speaker 5:our early shenanigans, he was able to come in and clean up a lot. It's like an adult showed up and put everything in order and, like
Speaker 1:One thing but also where you can, you know, have someone come in with with, you know, a coming from a kind of a different, different code base and be able to bring, like, a bunch of great I mean, we our ability to to to leverage Rust across many different systems, across Probus, across Omicron, across Crucible, I mean, has been, I think, really across Hubris for that matter.
Speaker 5:And we all talk to each other, and we're all like, oh, wait a minute. I'm doing this, and this is this is working really good, or it's not working really good. Then everyone else is like, oh, I'm gonna do that, or I'm not gonna do that, or, like, that, I could share it all around. So
Speaker 1:It's been it's been a really important element, I think, of of principal success. The great work, everyone. It's been fun. And and thanks, folks, for for prodding us to do this episode. This has been this it's been, way too long in coming.
Speaker 1:So, thank you very much for for encouraging us. We got we're gonna have a a lot more of these. I think we'll probably have I have to do some crystal follow ons at some point as well, but, I want James, Matt, Josh, of course, and Adam. I I guess, Adam, I do have to thank you for joining us. I mean, you kinda Nah.
Speaker 3:I would have been here anyway.
Speaker 1:Yeah. Thanks. So alright. Thanks, everyone. I will talk to you next time.
Creators and Guests